A bank is interested in identifying different attributes of its customers and below is the sample data of 150 customers. In the data table for the dummy variable Gender, 0 represents Male and 1 represents Female. And for the dummy variable Personal loan, 0 represents a customer who has not taken personal loan and 1 represents a customer who has taken personal loan.
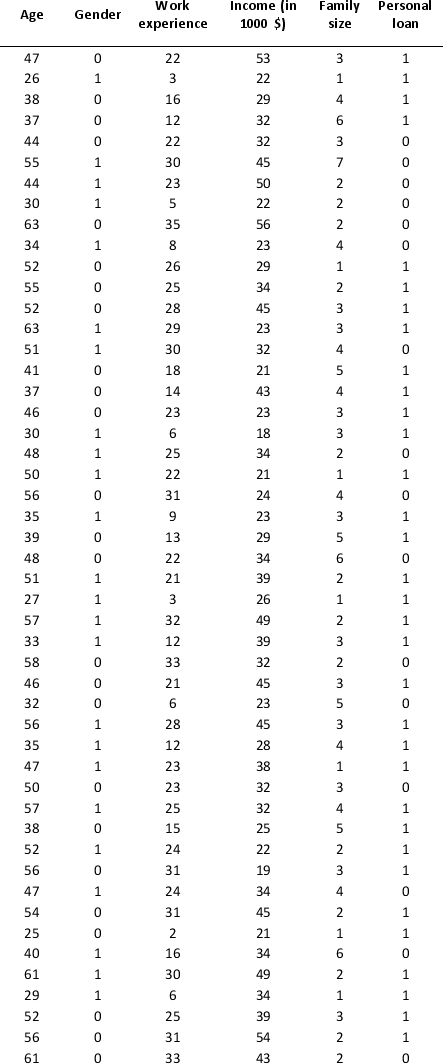
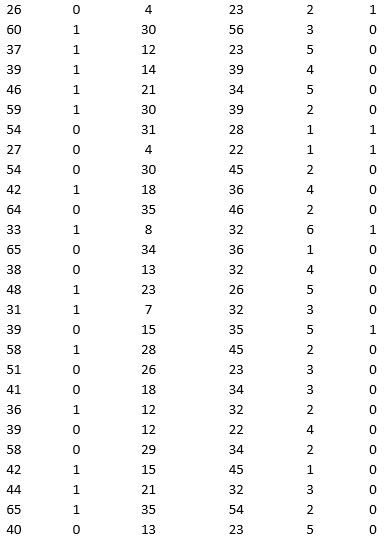
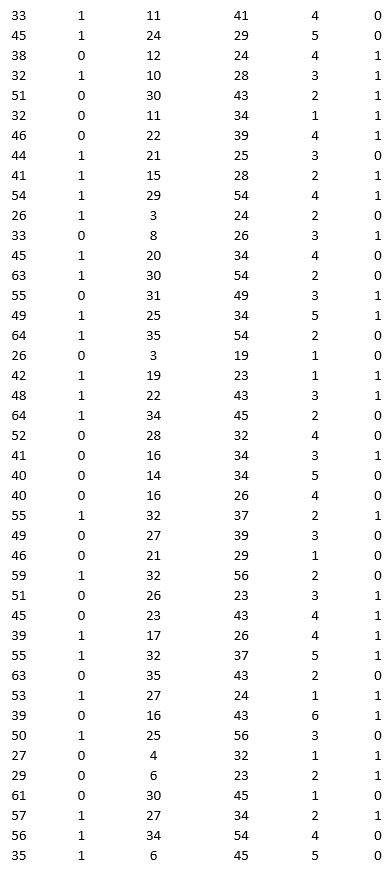
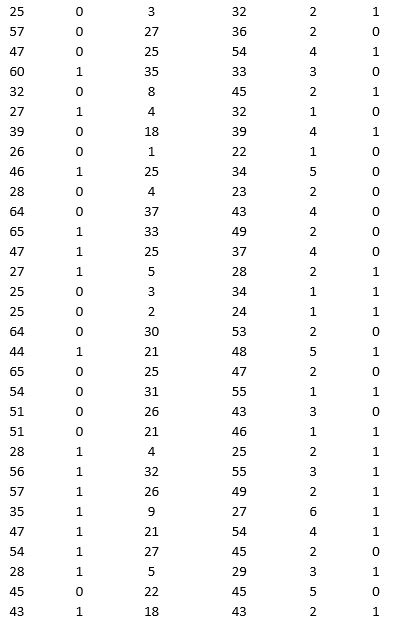
Partition the data into training (50 percent), validation (30 percent), and test (20 percent) sets. Classify the data using k-nearest neighbors with up to k = 10. Use Age, Gender, Work experience, Income (in 1000 $), and Family size as input variables and Personal loan as the output variable. In Step 2 of XLMiner's k-nearest neighbors Classification procedure, be sure to Normalize input data and to Score on best k between 1 and specified value. Generate lift charts for both the validation data and test data.
a. For the cutoff probability value 0.5, what value of k minimizes the overall error rate on the validation data? Explain the difference in the overall error rate on the training, validation, and test data.
b. Examine the decile-wise lift chart on the test data. Identify and interpret the first decile lift.
c. For cutoff probability values of 0.5, 0.4, 0.3, and 0.2, what are the corresponding Class 1 error rates and Class 0 error rates on the validation data?
Correct Answer:
Verified
View Answer
Unlock this answer now
Get Access to more Verified Answers free of charge
Q50: To examine the local housing market in
Q51: As part of the quarterly reviews, the
Q52: To examine the local housing market in
Q53: To examine the local housing market in
Q54: To examine the local housing market in
Q55: A bank is interested in identifying different
Q57: A research team wanted to assess the
Q58: To examine the local housing market in
Q59: A research team wanted to assess the
Q60: As part of the quarterly reviews, the
Unlock this Answer For Free Now!
View this answer and more for free by performing one of the following actions

Scan the QR code to install the App and get 2 free unlocks

Unlock quizzes for free by uploading documents