
Introductory Econometrics: A Modern Approach 6th Edition by Jeffrey M Wooldridge
Edition 6ISBN: 130527010XIntroductory Econometrics: A Modern Approach 6th Edition by Jeffrey M Wooldridge
Edition 6ISBN: 130527010XSuppose that the linear model, written in matrix notation,
![Suppose that the linear model, written in matrix notation, satisfies Assumptions E.1, E.2, and E.3. Partition the model as where X <sub>1</sub> is <i>n</i> × (<i>k</i><sub>1</sub> 1 1) and X <sub>2</sub> is <i>n</i> × <i>k</i><sub>2</sub>. <blockquote> (i) Consider the following proposal for estimating <i>?</i><sub>2</sub>. First, regress y on X <sub>1</sub> and obtain the residuals, say, ÿ . Then, regress ÿ on X <sub>2</sub> to get . Show that is generally biased and show what the bias is. [You should find in terms of <i>?</i><sub>2</sub>, X <sub>2</sub>, and the residual-making matrix M <sub>1</sub>.] (ii) As a special case, write where X <i><sub>k</sub></i> is an <i>n</i> × 1 vector on the variable <i>x</i><i><sub>tk</sub></i>. Show that where SSR<i><sub>k</sub></i> is the sum of squared residuals from regressing <i>x</i><i><sub>tk</sub></i> on 1, <i>x</i><i><sub>t</sub></i><sub>1</sub>, <i>x</i><i><sub>t</sub></i><sub>2</sub>, …, <i>x</i><i><sub>t, k</sub></i><sub>–</sub><sub>1</sub>. How come the factor multiplying <i>?</i><i><sub>k</sub></i> is never greater than one? (iii) Suppose you know <i> ? </i> <sub>1</sub>. Show that the regression y – X <sub>1</sub> <i> ? </i> <sub>1</sub> on X <sub>2</sub> produces an unbiased estimator of <i> ? </i> <sub>2</sub> (conditional on X ). </blockquote>](https://d2lvgg3v3hfg70.cloudfront.net/SMCC2709/791fa32f_42bf_4b17_8098_52aa793e419e_SMCC2709_11.jpg)
satisfies Assumptions E.1, E.2, and E.3. Partition the model as
![Suppose that the linear model, written in matrix notation, satisfies Assumptions E.1, E.2, and E.3. Partition the model as where X <sub>1</sub> is <i>n</i> × (<i>k</i><sub>1</sub> 1 1) and X <sub>2</sub> is <i>n</i> × <i>k</i><sub>2</sub>. <blockquote> (i) Consider the following proposal for estimating <i>?</i><sub>2</sub>. First, regress y on X <sub>1</sub> and obtain the residuals, say, ÿ . Then, regress ÿ on X <sub>2</sub> to get . Show that is generally biased and show what the bias is. [You should find in terms of <i>?</i><sub>2</sub>, X <sub>2</sub>, and the residual-making matrix M <sub>1</sub>.] (ii) As a special case, write where X <i><sub>k</sub></i> is an <i>n</i> × 1 vector on the variable <i>x</i><i><sub>tk</sub></i>. Show that where SSR<i><sub>k</sub></i> is the sum of squared residuals from regressing <i>x</i><i><sub>tk</sub></i> on 1, <i>x</i><i><sub>t</sub></i><sub>1</sub>, <i>x</i><i><sub>t</sub></i><sub>2</sub>, …, <i>x</i><i><sub>t, k</sub></i><sub>–</sub><sub>1</sub>. How come the factor multiplying <i>?</i><i><sub>k</sub></i> is never greater than one? (iii) Suppose you know <i> ? </i> <sub>1</sub>. Show that the regression y – X <sub>1</sub> <i> ? </i> <sub>1</sub> on X <sub>2</sub> produces an unbiased estimator of <i> ? </i> <sub>2</sub> (conditional on X ). </blockquote>](https://d2lvgg3v3hfg70.cloudfront.net/SMCC2709/a8f4eb4e_3aa0_4b5b_a890_2a82053e369f_SMCC2709_11.jpg)
where X1 is n × (k1 1 1) and X2 is n × k2.
(i) Consider the following proposal for estimating ?2. First, regress y on X1 and obtain the residuals, say, ÿ. Then, regress ÿ on X2 to get
. Show that
is generally biased and show what the bias is. [You should find
in terms of ?2, X2, and the residual-making matrix M1.]
(ii) As a special case, write
where Xk is an n × 1 vector on the variable xtk. Show that
where SSRk is the sum of squared residuals from regressing xtk on 1, xt1, xt2, …, xt, k–1. How come the factor multiplying ?k is never greater than one?
(iii) Suppose you know ?1. Show that the regression y – X1?1 on X2 produces an unbiased estimator of ?2 (conditional on X).
![Suppose that the linear model, written in matrix notation, satisfies Assumptions E.1, E.2, and E.3. Partition the model as where X <sub>1</sub> is <i>n</i> × (<i>k</i><sub>1</sub> 1 1) and X <sub>2</sub> is <i>n</i> × <i>k</i><sub>2</sub>. <blockquote> (i) Consider the following proposal for estimating <i>?</i><sub>2</sub>. First, regress y on X <sub>1</sub> and obtain the residuals, say, ÿ . Then, regress ÿ on X <sub>2</sub> to get . Show that is generally biased and show what the bias is. [You should find in terms of <i>?</i><sub>2</sub>, X <sub>2</sub>, and the residual-making matrix M <sub>1</sub>.] (ii) As a special case, write where X <i><sub>k</sub></i> is an <i>n</i> × 1 vector on the variable <i>x</i><i><sub>tk</sub></i>. Show that where SSR<i><sub>k</sub></i> is the sum of squared residuals from regressing <i>x</i><i><sub>tk</sub></i> on 1, <i>x</i><i><sub>t</sub></i><sub>1</sub>, <i>x</i><i><sub>t</sub></i><sub>2</sub>, …, <i>x</i><i><sub>t, k</sub></i><sub>–</sub><sub>1</sub>. How come the factor multiplying <i>?</i><i><sub>k</sub></i> is never greater than one? (iii) Suppose you know <i> ? </i> <sub>1</sub>. Show that the regression y – X <sub>1</sub> <i> ? </i> <sub>1</sub> on X <sub>2</sub> produces an unbiased estimator of <i> ? </i> <sub>2</sub> (conditional on X ). </blockquote>](https://d2lvgg3v3hfg70.cloudfront.net/SMCC2709/494c8e9f_a62c_4611_b740_948520836c36_SMCC2709_11.jpg)
![Suppose that the linear model, written in matrix notation, satisfies Assumptions E.1, E.2, and E.3. Partition the model as where X <sub>1</sub> is <i>n</i> × (<i>k</i><sub>1</sub> 1 1) and X <sub>2</sub> is <i>n</i> × <i>k</i><sub>2</sub>. <blockquote> (i) Consider the following proposal for estimating <i>?</i><sub>2</sub>. First, regress y on X <sub>1</sub> and obtain the residuals, say, ÿ . Then, regress ÿ on X <sub>2</sub> to get . Show that is generally biased and show what the bias is. [You should find in terms of <i>?</i><sub>2</sub>, X <sub>2</sub>, and the residual-making matrix M <sub>1</sub>.] (ii) As a special case, write where X <i><sub>k</sub></i> is an <i>n</i> × 1 vector on the variable <i>x</i><i><sub>tk</sub></i>. Show that where SSR<i><sub>k</sub></i> is the sum of squared residuals from regressing <i>x</i><i><sub>tk</sub></i> on 1, <i>x</i><i><sub>t</sub></i><sub>1</sub>, <i>x</i><i><sub>t</sub></i><sub>2</sub>, …, <i>x</i><i><sub>t, k</sub></i><sub>–</sub><sub>1</sub>. How come the factor multiplying <i>?</i><i><sub>k</sub></i> is never greater than one? (iii) Suppose you know <i> ? </i> <sub>1</sub>. Show that the regression y – X <sub>1</sub> <i> ? </i> <sub>1</sub> on X <sub>2</sub> produces an unbiased estimator of <i> ? </i> <sub>2</sub> (conditional on X ). </blockquote>](https://d2lvgg3v3hfg70.cloudfront.net/SMCC2709/720f008e_17fd_479c_8544_dbb62fdc8b0a_SMCC2709_11.jpg)
Step 1 of 4
Consider the linear model as,
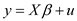
That is partitioned as,

Here,

Step 2 of 4
Step 3 of 4
Step 4 of 4
Why don’t you like this exercise?
Other


