
Introductory Econometrics: A Modern Approach 6th Edition by Jeffrey M Wooldridge
Edition 6ISBN: 130527010XIntroductory Econometrics: A Modern Approach 6th Edition by Jeffrey M Wooldridge
Edition 6ISBN: 130527010XFor positive random variables X and Y, suppose the expected value of Y given X is E(Y/X) = ?X. The unknown parameter shows how the expected value of Y changes with X.
(i) Define the random variable Z =Y/X. Show that E(Z) = ?.
(ii) Use part (i) to prove that the estimator W1 = n-1
(Yi /Xi) is unbiased for ?, where {(Xi,Yi): i = 1, 2,…., n} is a random sample
(iii) Explain why the estimator W2 =
, where the overbars denote sample averages, is not the same as W1. Nevertheless, show that W2 is also unbiased for ?.
(iv) The following table contains data on corn yields for several counties in Iowa. The USDA predicts the number of hectares of corn in each county based on satellite photos. Researchers count the number of “pixels” of corn in the satellite picture (as opposed to,for example, the number of pixels of soybeans or of uncultivated land) and use these to predict the actual number of hectares. To develop a prediction equation to be used for counties in general, the USDA surveyed farmers in selected counties to obtain corn yields in hectares. Let Yi= corn yield in county i and let Xi = number of corn pixels in the satellite picture for county i. There are n=17 observations for eight counties. Use this sample to compute the estimates of ? devised in parts (ii) and (iii). Are the estimates similar?
Plot | Corn Yield | Corn Pixels |
1 | 165.76 | 374 |
2 | 96.32 | 209 |
3 | 76.08 | 253 |
4 | 185.35 | 432 |
5 | 116.43 | 367 |
6 | 162.08 | 361 |
7 | 152.04 | 288 |
8 | 161.75 | 369 |
9 | 92.88 | 206 |
10 | 149.94 | 316 |
11 | 64.75 | 145 |
12 | 127.07 | 355 |
13 | 133.55 | 295 |
14 | 77.70 | 223 |
15 | 206.39 | 459 |
16 | 108.33 | 290 |
17 | 118.17 | 307 |
Step 1 of 5
(i)
Given that there are two positive random variables X and Y
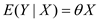
Also assume that the random variable 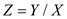
Then, this implies:
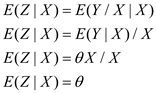
Using Property that follows the law of iterated expectations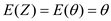
Step 2 of 5
Step 3 of 5
Step 4 of 5
Step 5 of 5
Why don’t you like this exercise?
Other


