
Introductory Econometrics: A Modern Approach 6th Edition by Jeffrey M Wooldridge
Edition 6ISBN: 130527010XIntroductory Econometrics: A Modern Approach 6th Edition by Jeffrey M Wooldridge
Edition 6ISBN: 130527010XThis exercise shows that in a simple regression model, adding a dummy variable for missing data on the explanatory variable produces a consistent estimator of the slope coefficient if the “missingness” is unrelated to both the unobservable and observable factors affecting y. Let m be a variable such that m = 1 if we do not observe x and m = 0 if we observe x. We assume that y is always observed. The population model is
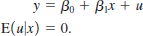
(i) Provide an interpretation of the stronger assumption
In particular, what kind of missing data schemes would cause this assumption to fail?
(ii) Show that we can always write
(iii) Let {(xi, yi, mi): i = 1, ..., n} be random draws from the population, where xi is missing when mi = 1. Explain the nature of the variable zi = (1 – mi )xi. In particular, what does this variable equal when xi is missing?
(iv) Let ? = P(m = 1) and assume that m and x are independent. Show that
where mx = E(x). What does this imply about estimating b1 from the regression yi on zi, i = 1, …, n?
(v) If m and x are independent, it can be shown that
where v is uncorrelated with m and z = (1 – m)x. Explain why this makes m a suitable proxy variable for mx. What does this mean about the coefficient on zi in the regression
(vi) Suppose for a population of children, y is a standardized test score, obtained from school records, and x is family income, which is reported voluntarily by families (and so some families do not report their income). Is it realistic to assume m and x are independent? Explain.
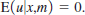
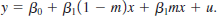
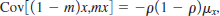

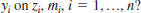
Step 1 of 8
(i)
E (??|??, ??) = 0 would mean that all other factors that affect y are uncorrelated with x and m, which is the missing data indicator. This assumption can get failed when the data is not MCAR and when analyses are based only on the complete case. This may lead to a bias.
Step 2 of 8
Step 3 of 8
Step 4 of 8
Step 5 of 8
Step 6 of 8
Step 7 of 8
Step 8 of 8
Why don’t you like this exercise?
Other


