Deck 14: Data Mining
Full screen (f)
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Exhibit 14.1
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
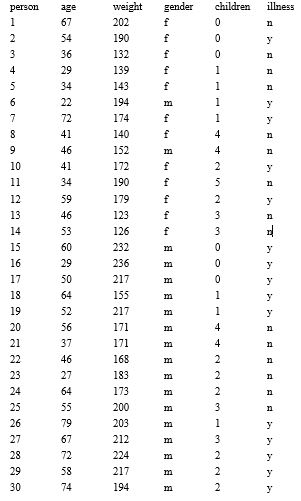
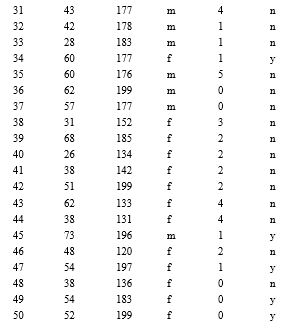
See Exhibit 14.1 - How well can logistic regression classify the people as having the illness or not
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - How well can logistic regression classify the people as having the illness or not
Question
Exhibit 14-3
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
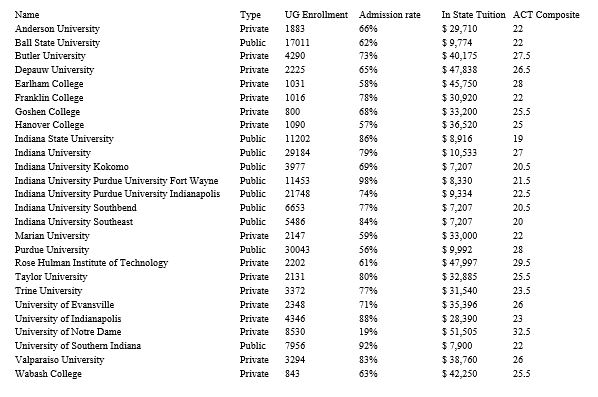
Refer to Exhibit 14-3 Choose any three college indices from 1 to 26 as trial values for the cluster centers. Complete the logicto return the name of the college or university associated with the index as well as the standardized numeric measures.
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Choose any three college indices from 1 to 26 as trial values for the cluster centers. Complete the logicto return the name of the college or university associated with the index as well as the standardized numeric measures.
Question
Exhibit 14-3
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Finally,calculate the minimum total distance to the cluster centers and use Evolutionary Solver to optimize the model.Describe the clusters that are formed.
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Finally,calculate the minimum total distance to the cluster centers and use Evolutionary Solver to optimize the model.Describe the clusters that are formed.
Question
Exhibit 14.1
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - How likely would a 40 year old,200 pound father of 2 children be to have the illness
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - How likely would a 40 year old,200 pound father of 2 children be to have the illness
Question
Exhibit 14-3
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to exhibit 14-3 As a first step in grouping the Indiana colleges and universities into clusters,standardize the numeric measures.
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to exhibit 14-3 As a first step in grouping the Indiana colleges and universities into clusters,standardize the numeric measures.
Question
Exhibit 14-3
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Next determine to which of the trial cluster centers each college or university would be assigned.
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Next determine to which of the trial cluster centers each college or university would be assigned.
Question
Exhibit 14.2
The age, weight, gender, and the number of children were tracked for 25 people. It is not known if these people have or have not been diagnosed with a certain illness. The data are provided in the table below.
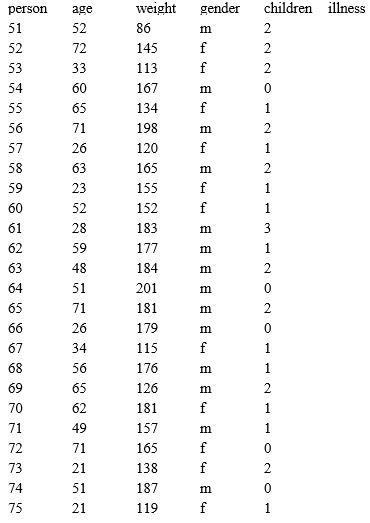
See Exhibit 14-2 Using Palisade's NeuralTools and the results from the prior problem,use the prediction data in this table to classify these 25 people as having been diagnosed with an illness or not.
The age, weight, gender, and the number of children were tracked for 25 people. It is not known if these people have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14-2 Using Palisade's NeuralTools and the results from the prior problem,use the prediction data in this table to classify these 25 people as having been diagnosed with an illness or not.
Question
Exhibit 14.1
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - What kind of person is more likely to be diagnosed with the illness
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - What kind of person is more likely to be diagnosed with the illness
Question
Exhibit 14-3
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Determine the distances for each college or university to each cluster center.
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Determine the distances for each college or university to each cluster center.
Question
Exhibit 14.1
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14-1 Use neural nets via Palisade's NeuralTools to classify the people as being diagnosed as having an illness or not. (Reserve 20% of the observations for testing.) How well does this method correctly classify people
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14-1 Use neural nets via Palisade's NeuralTools to classify the people as being diagnosed as having an illness or not. (Reserve 20% of the observations for testing.) How well does this method correctly classify people

Unlock Deck
Sign up to unlock the cards in this deck!
Unlock Deck
Unlock Deck
1/30
Play
Full screen (f)
Deck 14: Data Mining
1
Naive Bayes method assumes probabilistic independence across characteristics which means that the joint probability is the product of the probabilities of the individual characteristics.
True
2
SQL Server Analysis Services (SSAS)concentrates on which types of data mining
A) classification and clustering
B) market basket and forecasting
C) clustering and prediction
D) forecasting and classification
A) classification and clustering
B) market basket and forecasting
C) clustering and prediction
D) forecasting and classification
A
3
The K-Means clustering algorithm :
A) becomes an optimization model for choosing the best cluster centers.
B) determines the best value of K.
C) has an objective that maximizes the sum of the dissimilarity measures.
D) cannot be directly implemented in Excel.
A) becomes an optimization model for choosing the best cluster centers.
B) determines the best value of K.
C) has an objective that maximizes the sum of the dissimilarity measures.
D) cannot be directly implemented in Excel.
A
4
In the classification method,when data are partitioned into the training and testing subsets:
A) the data are divided evenly into the subsets.
B) the values of the dependent variable are known for both the training and the testing subsets.
C) the records in the subsets are chosen based on similar characteristics.
D) all of the above.
A) the data are divided evenly into the subsets.
B) the values of the dependent variable are known for both the training and the testing subsets.
C) the records in the subsets are chosen based on similar characteristics.
D) all of the above.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
5
If the probability of a restaurant being successful is 10% then the odds of it failing are 10 to 1.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
6
In data partitioning,data can be divided into training,testing,and prediction subsets.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
7
The function INDEX(A1:E5,4,3)would return the value in cell C4.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
8
Today's organizations rely on their quantitative experts,who have access to large amounts of data,to make sense of it in a timely manner.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
9
The last step of cluster analysis is to understand the shared characteristics of the observations in each cluster.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
10
Which of the following is false regarding neural networks
A) They attempt to mimic the complex behavior of the human brain.
B) They are synonymous with data mining.
C) They can be used to predict the value of a numeric dependent variable.
D) They do not provide an understanding of the contributions of individual explanatory variables.
A) They attempt to mimic the complex behavior of the human brain.
B) They are synonymous with data mining.
C) They can be used to predict the value of a numeric dependent variable.
D) They do not provide an understanding of the contributions of individual explanatory variables.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
11
The logistic function 1/(1+e -x )
A) is concave.
B) is convex.
C) is S-shaped.
D) takes on values between -1 and 1.
A) is concave.
B) is convex.
C) is S-shaped.
D) takes on values between -1 and 1.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
12
When classifying rare events,it is inadvisable to oversample.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
13
Better classification methods should improve lift,which is the increase in purchases gained through marketing to people with the highest probability of purchasing.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
14
Which of the following is not a classification method
A) Naive Bayes
B) Logistic regression
C) ROC curves
D) Neural networks
A) Naive Bayes
B) Logistic regression
C) ROC curves
D) Neural networks
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
15
Specificity,a measure of classification accuracy,reflects: (regard class 1 as yes and class 2 as no)
A) the portion of observations that are actually in class 1 that are classified as being in class 1.
B) the portion of observations that are actually in class 2 that are classified as being in class 2.
C) the portion of observations that are actually in class 2 that are classified as being in class 1.
D) the portion of observations that are classified as class 1 that are actually in class 1.
A) the portion of observations that are actually in class 1 that are classified as being in class 1.
B) the portion of observations that are actually in class 2 that are classified as being in class 2.
C) the portion of observations that are actually in class 2 that are classified as being in class 1.
D) the portion of observations that are classified as class 1 that are actually in class 1.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
16
Which of the following is false concerning a data warehouse
A) It is designed to study patterns in data.
B) It combines data from multiple sources.
C) It allows follow up responses to questions.
D) It supports the daily operations of the company.
A) It is designed to study patterns in data.
B) It combines data from multiple sources.
C) It allows follow up responses to questions.
D) It supports the daily operations of the company.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
17
For logistic regression:
A) the odds ratio is the independent variable.
B) the primary objective is to score each member.
C) the cutoff value is set to 0.5.
D) the magnitude of the regression coefficients can be compared for relative importance.
A) the odds ratio is the independent variable.
B) the primary objective is to score each member.
C) the cutoff value is set to 0.5.
D) the magnitude of the regression coefficients can be compared for relative importance.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
18
Which of the following is true of clustering methods
A) They are called supervised data mining techniques.
B) They require known values of the dependent variable.
C) They group observations into clusters based on predefined characteristics.
D) They are also known as segmentation methods.
A) They are called supervised data mining techniques.
B) They require known values of the dependent variable.
C) They group observations into clusters based on predefined characteristics.
D) They are also known as segmentation methods.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
19
Business analytics,while important,is only a part of the area of data mining.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
20
The primary advantage of neural networks is that they provide more accurate predictions,especially when the relationships are linear.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
21
Exhibit 14.1
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - How well can logistic regression classify the people as having the illness or not
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - How well can logistic regression classify the people as having the illness or not
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
22
Exhibit 14-3
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Choose any three college indices from 1 to 26 as trial values for the cluster centers. Complete the logicto return the name of the college or university associated with the index as well as the standardized numeric measures.
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Choose any three college indices from 1 to 26 as trial values for the cluster centers. Complete the logicto return the name of the college or university associated with the index as well as the standardized numeric measures.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
23
Exhibit 14-3
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Finally,calculate the minimum total distance to the cluster centers and use Evolutionary Solver to optimize the model.Describe the clusters that are formed.
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Finally,calculate the minimum total distance to the cluster centers and use Evolutionary Solver to optimize the model.Describe the clusters that are formed.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
24
Exhibit 14.1
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - How likely would a 40 year old,200 pound father of 2 children be to have the illness
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - How likely would a 40 year old,200 pound father of 2 children be to have the illness
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
25
Exhibit 14-3
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to exhibit 14-3 As a first step in grouping the Indiana colleges and universities into clusters,standardize the numeric measures.
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to exhibit 14-3 As a first step in grouping the Indiana colleges and universities into clusters,standardize the numeric measures.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
26
Exhibit 14-3
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Next determine to which of the trial cluster centers each college or university would be assigned.
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Next determine to which of the trial cluster centers each college or university would be assigned.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
27
Exhibit 14.2
The age, weight, gender, and the number of children were tracked for 25 people. It is not known if these people have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14-2 Using Palisade's NeuralTools and the results from the prior problem,use the prediction data in this table to classify these 25 people as having been diagnosed with an illness or not.
The age, weight, gender, and the number of children were tracked for 25 people. It is not known if these people have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14-2 Using Palisade's NeuralTools and the results from the prior problem,use the prediction data in this table to classify these 25 people as having been diagnosed with an illness or not.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
28
Exhibit 14.1
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - What kind of person is more likely to be diagnosed with the illness
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14.1 - What kind of person is more likely to be diagnosed with the illness
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
29
Exhibit 14-3
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Determine the distances for each college or university to each cluster center.
Information for 26 colleges and universities in the state of Indiana is provided in the table below. The following questions contain a sequence of steps for executing the K-Means Clustering Method.
Refer to Exhibit 14-3 Determine the distances for each college or university to each cluster center.
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
30
Exhibit 14.1
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14-1 Use neural nets via Palisade's NeuralTools to classify the people as being diagnosed as having an illness or not. (Reserve 20% of the observations for testing.) How well does this method correctly classify people
The age, weight, gender, and the number of children were tracked for 50 people who either have or have not been diagnosed with a certain illness. The data are provided in the table below.
See Exhibit 14-1 Use neural nets via Palisade's NeuralTools to classify the people as being diagnosed as having an illness or not. (Reserve 20% of the observations for testing.) How well does this method correctly classify people
Unlock Deck
Unlock for access to all 30 flashcards in this deck.
Unlock Deck
k this deck
Unlock Deck
Unlock for access to all 30 flashcards in this deck.



